
Open Source AI Models vs Closed Source Models: What’s the Difference?
If you want the short answer, open source AI models give you more control, while closed source AI models give you more convenience. Open models are better when you want to run a model locally, customize it deeply, or avoid depending on one vendor. Closed models are better when you want a polished API or app, managed infrastructure, and less operational work.
The important catch is terminology. In everyday conversation, people often say open source AI when they really mean open-weight AI. Those are not always the same thing. The Open Source Initiative says open source AI should give people the freedom to use, study, modify, and share the system, and it specifically says that open source models and weights should include the data information and code used to derive those parameters. That is stricter than simply publishing downloadable weights.
This article is for readers trying to understand the practical difference without getting buried in licensing jargon. As of April 10, 2026, the easiest way to think about it is this: open or open-weight models optimize for control and flexibility; closed models optimize for ease, integration, and managed service.
Key Takeaways
- Open source AI is the most open category, but many popular releases are more accurately called open-weight rather than fully open source.
- Closed source AI usually means you access the model through a vendor app or API, but you do not receive the weights, training pipeline, or redistribution rights.
- Open or open-weight models are strongest when you need local deployment, custom fine-tuning, cost control at scale, or deeper technical control.
- Closed models are strongest when you need fast setup, built-in tooling, managed safety systems, and lower infrastructure overhead.
- Privacy is not a simple open-versus-closed question. Open models can give you more deployment control, but some closed vendors also offer strong business privacy commitments.
- For most beginners, the right choice is not ideological. It is about workflow fit, team capacity, and risk tolerance.
Table of Contents
- What open source AI really means
- What closed source AI means
- The main differences that matter in practice
- Where open or open-weight models win
- Where closed models win
- How to choose the right option
- FAQ
What Open Source AI Really Means
The phrase open source AI sounds simple, but it covers several different realities.
The strict definition comes from the Open Source AI Definition from the Open Source Initiative. Under that definition, an open source AI system should let users:
- use the system for any purpose
- study how it works
- modify it
- share it with or without modifications
That is why the OSI also says that open source models and open source weights should include parameters, code, and data information needed to understand and modify the system. In other words, a downloadable model file alone does not automatically settle the question.
In real-world AI discussions, you will usually see three buckets:
| Term | What you usually get | What you often do not get |
|---|---|---|
| Open source AI | Weights, code, and enough supporting information to use, study, modify, and share the system | Not much is hidden if it genuinely meets the definition |
| Open-weight AI | Downloadable weights and usually inference code or framework support | Full training pipeline, full data transparency, or OSI-level openness |
| Closed source AI | API or app access to a hosted model | Weights, training code, full model internals, broad redistribution rights |
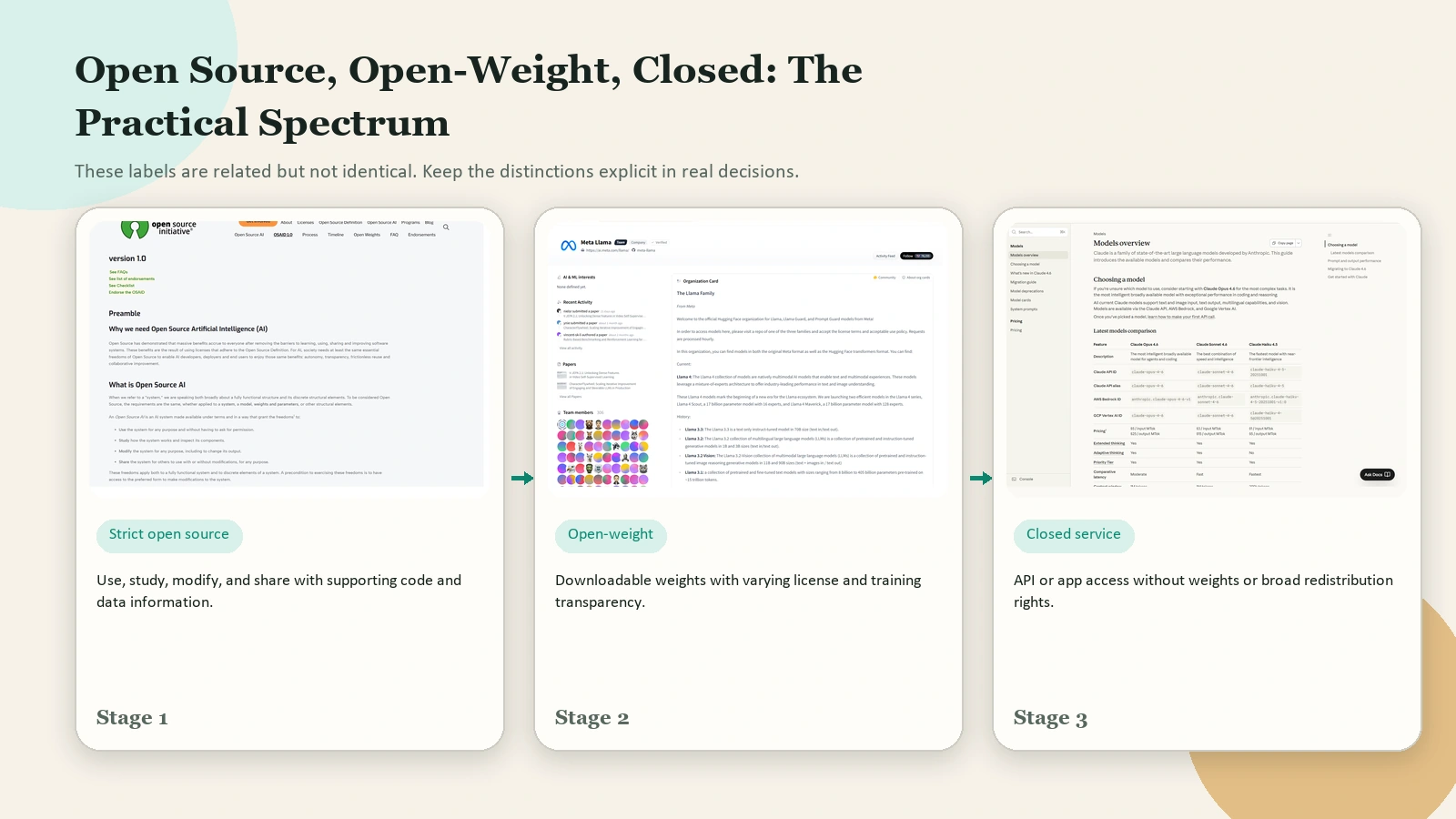 Caption: Most confusion comes from labeling everything open. The useful distinction is strict open source, open-weight, and closed service access.
Caption: Most confusion comes from labeling everything open. The useful distinction is strict open source, open-weight, and closed service access.
This distinction matters because many popular models marketed as “open” are actually open-weight with specific license terms, not universally open in the software sense.
For example, OpenAI’s gpt-oss-120b and gpt-oss-20b are explicitly described as open-weight reasoning models under an Apache 2.0 license. Google describes Gemma 3 as a family of open models with open weights. Meta’s official Llama organization on Hugging Face makes Llama weights available, but it also says users must accept the license terms and acceptable use policy before access is granted. That tells you immediately that openness exists on a spectrum.
What Closed Source AI Means
Closed source AI models are proprietary systems that you typically access through:
- a hosted chatbot
- a vendor API
- an enterprise workspace
- a managed platform integration
You can use the model, but you usually cannot inspect or redistribute the weights, retrain the system freely, or run the exact model however you want.
That does not automatically make closed models bad. In practice, closed models often come bundled with:
- better managed uptime
- simpler onboarding
- built-in tool use
- vendor-maintained safety layers
- enterprise admin controls
- support and compliance documentation
Closed models are often easier to adopt because someone else is handling the hosting, scaling, patching, and deployment complexity for you.
The Main Differences That Matter in Practice
Here is the practical comparison most teams actually care about.
| Dimension | Open or open-weight models | Closed source models |
|---|---|---|
| Weights access | Usually yes | No |
| Deployment | Can often run locally, on your own cloud, or on-prem | Usually vendor-hosted |
| Customization | Deep fine-tuning, quantization, system-level control | Usually limited to prompting, APIs, and vendor-approved tuning paths |
| Operations | You own more of the infra burden | Vendor owns more of the infra burden |
| Cost shape | More setup cost, can be efficient at scale | Easier to start, ongoing usage often tied to tokens, seats, or platform pricing |
| Safety and updates | You control the model and guardrails, but you also own more responsibility | Vendor ships updates, moderation systems, and managed controls |
| Vendor dependence | Lower if you can self-host or swap models | Higher because your workflow depends on one provider’s platform |
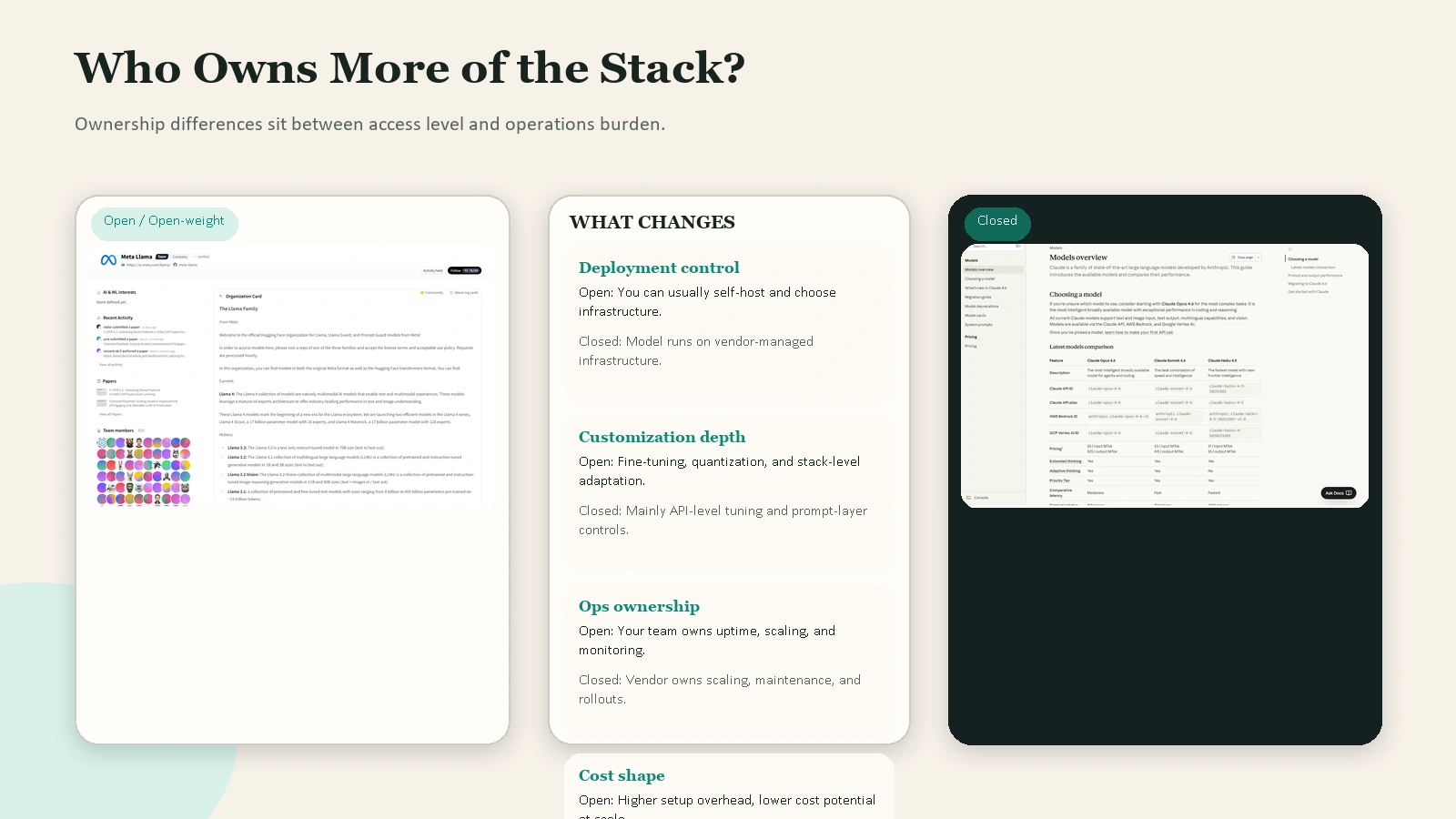 Caption: The practical difference is not only the model. It is who runs the infrastructure, who controls deployment, and who absorbs the operational work.
Caption: The practical difference is not only the model. It is who runs the infrastructure, who controls deployment, and who absorbs the operational work.
1. Access and inspectability
This is the biggest difference.
With open or open-weight models, you can usually download the model, inspect how it behaves, benchmark it in your own environment, and sometimes modify it at a deeper level. That matters for research, self-hosting, latency tuning, and integration into custom pipelines.
With closed models, you are usually working with an interface, not the model artifact itself. You see the service surface, not the underlying system.
2. Deployment control
Open or open-weight models are attractive when deployment control matters. You can often run them:
- on your own servers
- in a private cloud
- on edge hardware
- inside a restricted environment
That is one reason open releases are attractive to developers and enterprises with strict infrastructure preferences.
The current official examples show how broad this can be. OpenAI says gpt-oss-120b and gpt-oss-20b are designed for flexible deployment, with the 120b model able to run on a single 80 GB GPU and the 20b model able to run with 16 GB of memory. Google says Gemma 3 is available in 5 parameter sizes: 270M, 1B, 4B, 12B, and 27B, which is exactly the kind of range that makes open or open-weight deployment attractive for different hardware budgets.
Closed models usually give you less control over where the model runs, but they also remove a large amount of operational work.
3. Customization depth
If you want to fine-tune, quantize, distill, or embed a model into a more specialized system, open or open-weight models usually give you more room to work.
That flexibility is valuable when:
- you need a domain-specific model
- you want local inference
- you need low-level latency optimization
- you want to test multiple deployment frameworks
Closed models can still be customized, but usually within narrower boundaries. You may get prompt engineering, tool calling, structured outputs, custom GPTs, platform-specific fine-tuning, or vendor-managed adapters. That is useful, but it is not the same as owning the model artifact.
4. Privacy and compliance posture
Many people assume open models always win on privacy. That is only partly true.
If you self-host an open or open-weight model, you can keep the workload inside your own environment. That gives you more control over where data goes, how long logs are retained, and how the system is monitored.
But closed models are not automatically weak on privacy. OpenAI’s current business data privacy page states that, by default, it does not use data from ChatGPT Enterprise, ChatGPT Business, ChatGPT Edu, ChatGPT for Healthcare, ChatGPT for Teachers, or the API platform to train or improve models, and that qualifying organizations can choose retention settings including zero data retention on the API platform.
So the real question is not “open or closed?” It is:
- where will the model run?
- what contract and controls apply?
- who owns the logs, retention, and access layer?
5. Cost structure
Open or open-weight models are often described as “free,” but that is incomplete.
You may not pay a per-token API fee, but you still pay for:
- GPUs or CPUs
- storage
- inference infrastructure
- engineering time
- monitoring and security
Closed models are often easier to start with because you can begin using them immediately. The tradeoff is that long-term cost may grow with heavier usage, especially if your workflow depends on a commercial API at scale.
6. Safety, moderation, and maintenance
Open releases increase control, but they also increase responsibility.
OpenAI’s gpt-oss model card explicitly notes that open models have a different risk profile from proprietary ones because once released, determined attackers can fine-tune them to bypass safety refusals or optimize for harm. That is a useful reminder: openness can improve flexibility and research, but it can also reduce a vendor’s ability to enforce safety after release.
Closed models usually make safety someone else’s infrastructure problem first. That does not eliminate risk, but it changes who is responsible for shipping updates, moderation layers, abuse detection, and rollback controls.
Where Open or Open-Weight Models Win
Open or open-weight models are often the better choice when you need one or more of these conditions:
You need local or private deployment
If you must run inference on your own hardware or in your own cloud, open or open-weight models are usually the most practical route.
You want deep technical control
This includes quantization, custom routing, self-hosted inference stacks, model merging, experimental fine-tuning, and specialized evaluation.
You want less vendor lock-in
If you build around a portable model and standard tooling, you have more leverage to swap infrastructure or upgrade on your own schedule.
You have the engineering capacity
Open models reward teams that can manage deployment, benchmarking, security, observability, and model lifecycle work. If you do not have that capacity, the flexibility advantage can collapse into operational drag.
You are building for hardware diversity
Google’s Gemma 3 overview highlights why open model families can be appealing here: the same family spans 270M to 27B sizes, with 128K context on the 4B, 12B, and 27B variants and support for over 140 languages. That kind of size ladder is useful when you want one family that can stretch from lightweight experimentation to more serious workloads.
Where Closed Models Win
Closed models are often the better choice when simplicity matters more than maximum control.
You want the fastest path to production
If your goal is to ship a feature quickly, a hosted API or managed workspace is usually faster than building and operating your own inference stack.
You want vendor-managed tooling
Closed models often arrive with the rest of the stack:
- authentication
- billing
- dashboards
- tool calling
- safety systems
- rate limiting
- enterprise controls
That reduces the number of moving parts your team must own.
You do not want to maintain model infrastructure
Self-hosting is real work. Someone has to handle scaling, availability, GPU utilization, logging, abuse prevention, and patching. Closed models are attractive when you want the model to behave more like a managed SaaS dependency.
You need a cleaner beginner workflow
For individual learners and small teams, closed models are often easier because you can focus on prompts, review, and workflow design instead of infrastructure.
How to Choose the Right Option
For most readers, this decision should not be framed as a tribal debate.
A better decision framework is:
- Choose open or open-weight when you need local control, deeper customization, hardware flexibility, or less vendor dependence.
- Choose closed when you need the fastest setup, managed reliability, and the lowest operational burden.
- Choose a hybrid setup when you want both.
Many teams already do this in practice:
- they use a closed model for fast general-purpose work
- they use an open or open-weight model for private workloads, edge deployment, or cost-sensitive high-volume tasks
- they keep the workflow layer portable so they can swap models later
 Caption: The right first choice depends on whether you need control, convenience, or a hybrid workflow.
Caption: The right first choice depends on whether you need control, convenience, or a hybrid workflow.
A practical beginner rule
If you are still learning, start with this simple rule:
- use a closed model if you want to learn AI workflows quickly
- use an open or open-weight model when you have a specific reason to control deployment or customize the model
That keeps the choice grounded in real work, not ideology.
FAQ
Are open source AI models always free?
No. The model license may let you download or use the weights freely, but running the model still costs money in compute, storage, monitoring, and engineering time. Open models can lower software access costs, but they do not eliminate infrastructure costs.
Is open source AI better for privacy?
Sometimes, but not automatically. If you self-host the model, you usually gain more control over data flow and retention. But some closed vendors also offer strong business privacy controls, so the right comparison is deployment setup plus contract terms, not license label alone.
What is the difference between open source and open-weight AI?
Open-weight usually means the model weights are downloadable. Open source, in the stricter OSI sense, goes further and includes the freedoms to use, study, modify, and share the system, plus the supporting code and data information needed to understand how it was derived.
Are closed models always better quality?
Not always. Quality depends on the task, the model family, latency requirements, prompting, and how much customization you need. Closed models often win on convenience and integrated tooling, but open or open-weight models can be a better fit when control and deployability matter more.
What should a small team choose first?
Most small teams should start with the simplest setup that helps them learn. That usually means a managed closed model first. Move toward open or open-weight models when you have a clear need for self-hosting, custom deployment, or tighter infrastructure control.
Conclusion
The difference between open source AI models and closed source models is not just about philosophy. It is about access, control, responsibility, and operational tradeoffs.
If you need flexibility, self-hosting, and deeper customization, open or open-weight models are often the better fit. If you need speed, convenience, and managed infrastructure, closed models are often the better fit. And if you are a beginner, the smartest move is usually to choose the option that helps you build a reliable workflow first, then upgrade your model strategy once your needs are clearer.
If you want the next practical step, map one real task in your work to this question: Do I need more control, or do I need less operational friction? That answer will usually tell you which side to start with.
Future Internal Link Opportunities
No live internal targets were available from article-wordpress-tracking.csv on April 10, 2026, so these remain future link opportunities rather than in-body links.
- /blog/what-is-ai-fluency
- /blog/how-to-review-ai-output-before-you-trust-it
- /blog/privacy-basics-for-everyday-ai-use
- /blog/best-ai-tools-for-everyday-work